Editor's Note: With the investment of a large number of resources in the industry, big data and large-scale GPU clusters have brought about a comprehensive industry in the field of computer vision, and in many competitions, even achieved far more academic achievements. At the top conferences in the AI ​​field, more and more excellent jobs come from giants such as Google, Facebook, BAT or some new startups.
It is worth noting that the current major advances and applications of the industry are largely dependent on high-cost, supervised, deep learning. In many practical scenarios, there is a problem that the data acquisition cost is too high or even impossible to obtain. Therefore, in the case of insufficient data, how to use weak supervision or even unsupervised learning is not only a topic of wide concern in the academic world, but also a new challenge facing the industry.
Lin Shu, Director of R&D of Shangtang Technology and Professor of Sun Yat-Sen University, will lead everyone to explore the new challenges of “post-deep learning era†from the perspectives of industry and academic innovation.

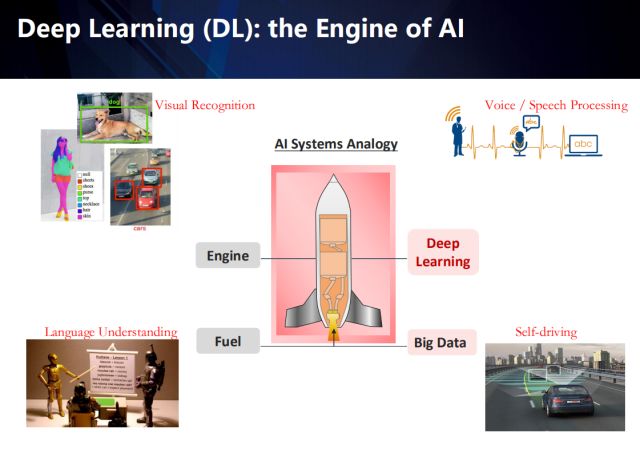
If the AI ​​system is compared to a rocket, then big data is its fuel, and deep learning is its engine. With the blessing of big data and GPU computing power, deep learning has made breakthroughs in many fields, such as visual image understanding, attribute recognition, object detection, natural language processing, and even automatic driving. Of course, the vertical application scenario is an indispensable factor in the landing of AI technology. This is actually the biggest advantage of doing research in the industry - guiding the development of technology from real needs, and the research in academia is often based on some The actual assumptions.
Based on visual image understanding, the AI ​​algorithm is learned from the labeled data to realize the corresponding visual recognition task. The upper left corner shows the object detection and attribute recognition application in visual image understanding.

It is worth noting that the successful application of deep learning in the field of computer vision relies heavily on supervised data, which means a large amount of clean data that is fully labeled (such as data in the field of face recognition). However, such data means very high costs. In real-life scenarios, there are often weakly supervised or data obtained from the Internet (such as data on social media), and unlabeled or noisy data (such as smart city and autopilot applications). data).
Professor LeCun used the cake on the right to describe the difference between supervised learning, unsupervised learning, and reinforcement learning. Here is a description of the difference between the three types of data: completely labeled clean data like a gold foil cherry on a cake Sweet but expensive; and weakly labeled or Internet-crawled data, like the cream on a cake, is sweet but also available; and unlabeled or noisy data is not too sweet but at a lower cost.

In this report, I will first introduce how deep learning applies to visual understanding, and then introduce the latest deep learning paradigm in three ways:
Support learning by enriching multiple sources of weak supervisory information
Self-driven algorithm, self-learning with high cost performance (performance/supervised information cost)
Unsupervised domain adaptive learning
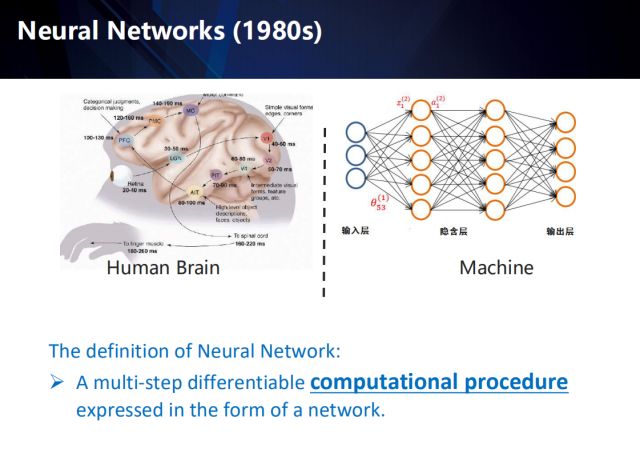
First, introduce the basic concept of deep learning. Deep learning is defined as a differential computing process that is presented in the form of a network and covers multiple steps. Speaking of deep learning, we must start with the neural network of the 1980s. The original intention of neural network naming is to pay tribute to the neural network in the human brain. So how do you deal with visual signals in the human brain?
First, the retina enters a visual signal that passes through the outer ligament of the LGN and reaches the visual cortex V1 - V5, where V1 is sensitive to edges and corners, V2 captures motion information, and V4 is sensitive to part objects, such as human eyes, arms, etc., and finally arrives. AIT, to handle high-level information: faces, objects, etc. It is sent to the PFC decision-making layer, and finally the MC issues an instruction. So the human brain processes the visual signal as a process from shallow to deep, and in the process, it is not a single process, it is also time-series, that is, it is utilized in processing each signal. Previous timing information.
The form and computational process of deep neural networks is very different from that of human brains, but its invention is indeed inspired by neural signal processing. For example, the classic perceptron model is actually a simulation of the most basic concepts of neurons. The upper right shows the multilayer perceptron invented in 1980.

From the multi-layer perceptron in the 1980s to the convolutional neural network in 2010, it has gone through a process of reducing the number of layers from as little as possible, from shallow to deep, by solving the problem of network gradient disappearance and generalization, and data and The GPU blessing, it finally realized a one-stop end-to-end network.
Since 2010, the deep learning method has achieved far more than traditional machine learning methods. Especially with the continuous expansion of the training data set, the traditional method quickly touches the precision ceiling. In contrast, the depth method has a constant prediction accuracy. Upgrade. This concludes several key points of this wave of deep learning technology innovations, including new network optimization methods such as ReLu, Batch Normally, Skip Connection, etc.; from mathematics/knowledge-driven to data-driven research ideas; Gradually transition to joint end-to-end joint optimization; from avoiding over-fitting learning to avoiding under-fitting learning; a large number of open source code and initialization models emerge.
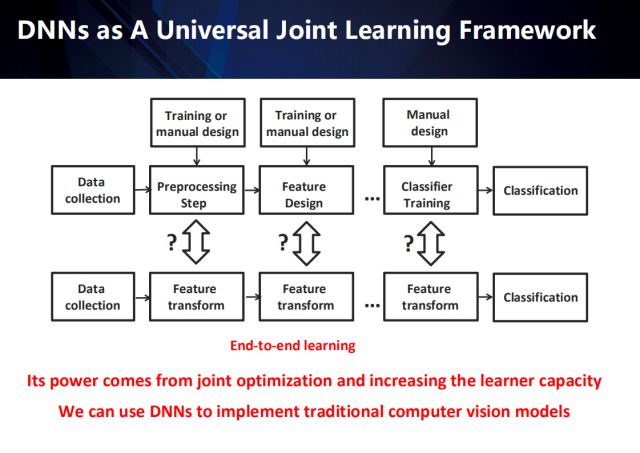
Traditional pattern recognition tasks can be roughly summarized into several independent steps: including data acquisition, data preprocessing, feature extraction, classifier training, and final classification. Among them, the data preprocessor and feature extractor are designed to be driven by experience. Deep learning, by combining preprocessing, feature extraction and classification training tasks, has led to an end-to-end feature conversion network with stronger representation capabilities.
In the evolution of traditional pattern recognition methods to deep methods, we have become more and more aware of the importance of learning, and feature learning has evolved into an end-to-end learning system. Preprocessing in traditional methods is not a must. Be integrated into the end-to-end system. It seems that feature learning affects the performance of all pattern recognition tasks, however, we ignore the importance of data collection and evaluation.
Next, we illustrate how traditional methods evolved into deep methods.
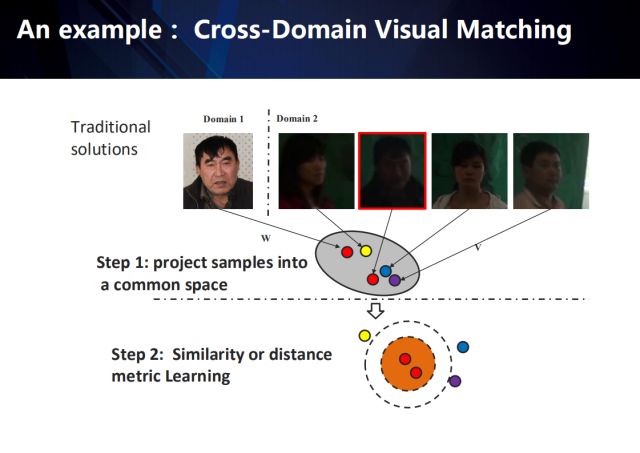
For example, the cross-domain visual matching task (matching from the data in domain 2 to the target in the given domain 1), the traditional method generally involves the following two steps:
First, project samples from different fields into a common feature space (feature learning);
Then, using the similarity or distance metric learning method, a distance metric is learned to characterize the similarity between features in this public space (similarity metric learning).
So how do you integrate this measure of similarity into deep neural networks and do end-to-end learning?
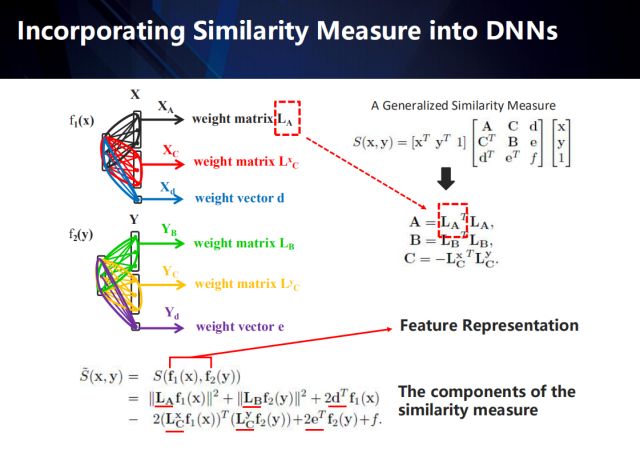
How to integrate the similarity measure into feature extraction?
Take the similarity measure method represented by the upper right formula as an example (presentation and derivation of the measurement model, please participate in the relevant paper), we can decompose the measurement model into the neural network - represent the original fully connected network into several A structured network that matches the metric model. Through the reverse conduction of error, the measurement model and the convolution feature can be jointly studied and unified. The detailed process is as follows:
In the upper right formula, the A matrix is ​​the autocorrelation matrix between the samples in the field of the x sample, semipositive definite; the B matrix represents the autocorrelation matrix between the samples in the field of the y sample, semipositive definite; the C matrix is ​​between the two domain samples. Correlation matrix.
After the expansion, we can find that its components contain six different variables that express the distance measurement model (each domain contains 2 matrices and 1 vector) in addition to the features extracted by the network from different domains. The upper left part of the figure shows the process of integrating the decomposed distance metrics into the neural network—a structured network model.
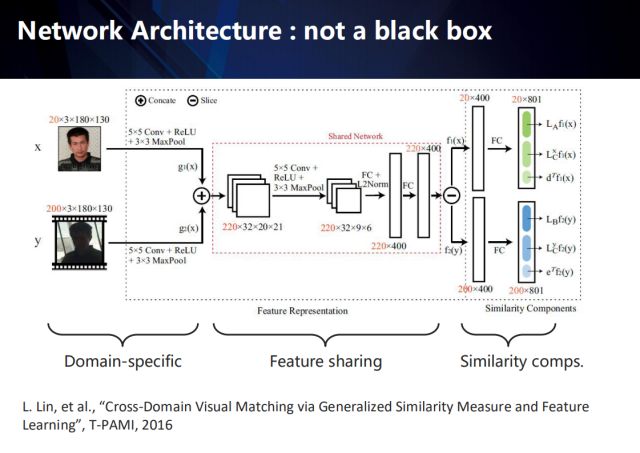
From this point of view, the deep network is not a complete black box. By introducing domain knowledge and structured models, it can have a certain degree of macroscopic interpretation.
Taking the cross-domain visual matching algorithm as an example, its internals can be summarized into three parts: domain-unique layer, feature sharing layer, and similarity measure.
The entire end-to-end network is shown in the figure, and each part is interpretable.
In the domain-unique layer, the network extracts the unique characteristics of the domain for data of different domains;
In the feature sharing layer, we first fuse the features of different domains, and then project the merged features into the shared space, and then reversely disassemble the features of the respective domains in the shared space;
Finally, the similarity measure is used to obtain the matching similarity between different domain samples.
Related work was published at T-PAMI 2016, which achieved state-of-the-arts in many areas at the time.

Our validation benchmark includes several main tasks: age face verification, cross-camera re-recognition, matching between sketches and photos, and matching between still and static videos.
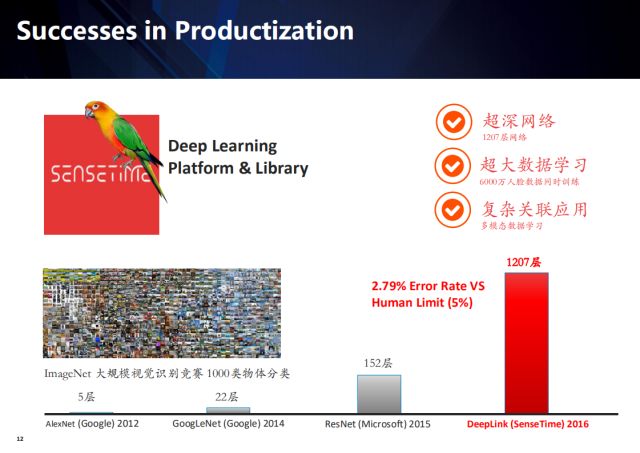
In contrast, deep learning in the company gives full play to the advantages of massive computing resources and sufficient data volume. The well-designed algorithm advantages of the academic community are easily offset by the ability to engineer.
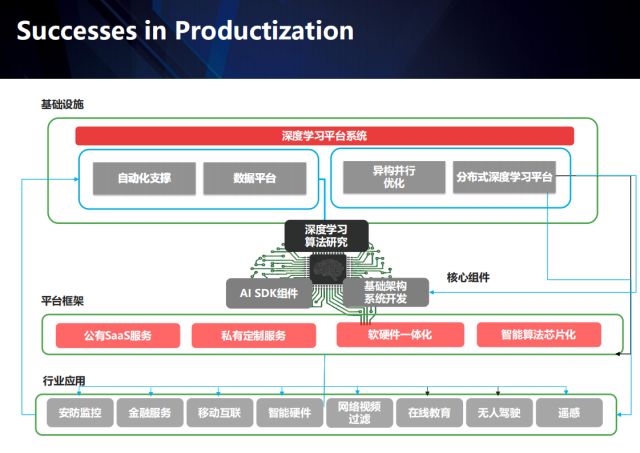
In addition, the difference between academics only focuses on the model of the algorithm itself. In the industrial world, there are a lot of links involved in different industries. Different scenarios will lead to different problems. At this time, forming a data loop through the application scenario becomes the key. Shangtang has invested a lot of resources in building basic platforms and engineering teams. Through in-depth vertical fields, accumulating industry data and establishing industry barriers, it is gradually transitioning from AI platform companies to AI products companies.

With the investment of a large number of resources in the industry, big data and large-scale GPU clusters have brought about a comprehensive industry in the field of computer vision. In many competitions, even in the competition, it has achieved far more achievements than academic circles. It is worth noting that these advances in the industry depend on a large amount of fully supervised data, and in many practical scenarios, there are problems in that data acquisition costs are too high or even impossible to obtain. Since 2012, the rapid development of deep learning technology has achieved a lot of successful applications in various fields such as image and voice. If these five years are regarded as a new technological era, then in the era of “post-depth learningâ€, we What more should you focus on?
I give some thoughts in this report - introduce three new deep learning paradigms:
Support learning by enriching multiple sources of weak supervisory information
Self-driven, cost-effective self-learning
Unsupervised domain adaptive learning
Learning with Weak and Rich Supervisions

First, we will introduce how to enrich learning by enriching multiple sources of weak supervisory information.

Due to the variety of web forms, data obtained from the Internet often has multiple types of labels, but the accuracy of the labels is not guaranteed, and label noise is often present. Therefore, this type of data can be seen as weakly supervised information with rich multiple sources. Then, we consider correcting the label by learning weak supervision information from multiple sources.
A large amount of data is sent together with a label with a small amount of noise into a deep convolutional neural network to detect the label noise and correct it. For example, the image on the right shows the correction of the label by fusing the image data and the corresponding text description.
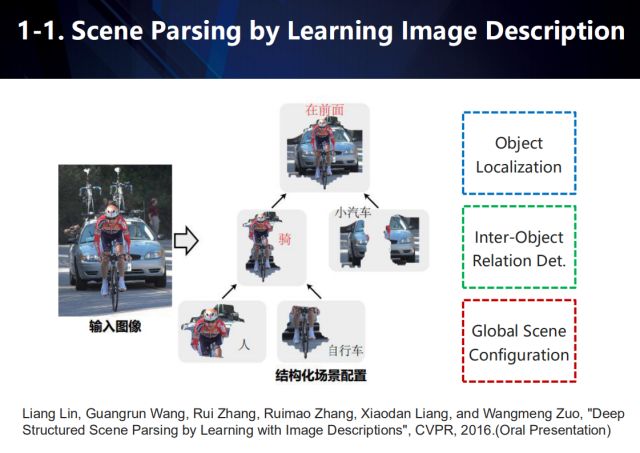
In the scene resolution task, we analyze the scene by learning the description of the image. As shown in the figure, object positioning is used to acquire objects with significant semantics in the scene, and then a structured scene configuration is constructed according to the interaction relationship between the objects.
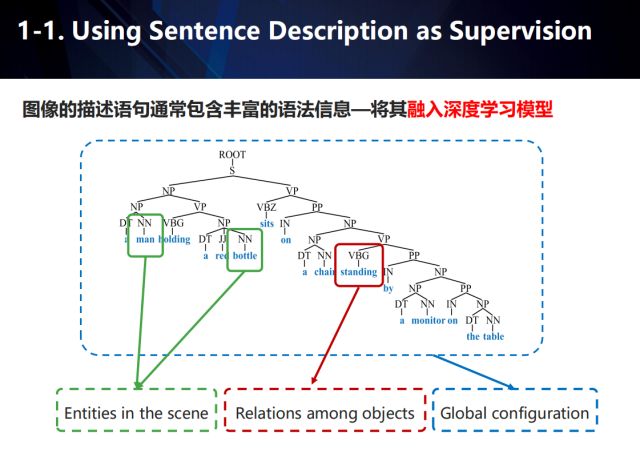
The description of the image usually contains rich grammar information. If it can be incorporated into the deep learning model, it can be regarded as an auxiliary monitoring tool. Taking the application of image description as an example, as shown in the figure, we use green boxes to represent the entities appearing in the scene, red boxes to represent the relationship between entities, and blue boxes to represent the global configuration of the scene.
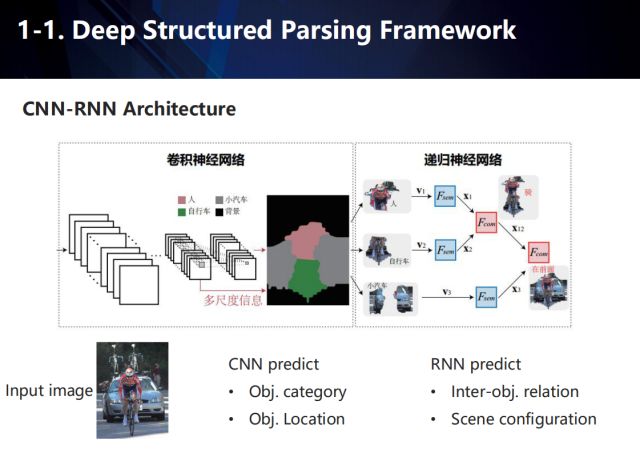
Based on the above, we propose an end-to-end, deep structured scene analysis framework combining convolutional neural networks and recurrent neural networks. After the input image passes through the convolutional neural network, a score map and a feature representation of each pixel are generated for each semantic category, and then each pixel is classified according to the score maps, and the pixels of the same category are aggregated together, and finally Get the feature representation of v targets in the scene. The characteristics of the v targets are then fed into the recurrent neural network and mapped to a semantic space, and semantics are extracted to predict the interaction between objects. The training process is as follows:
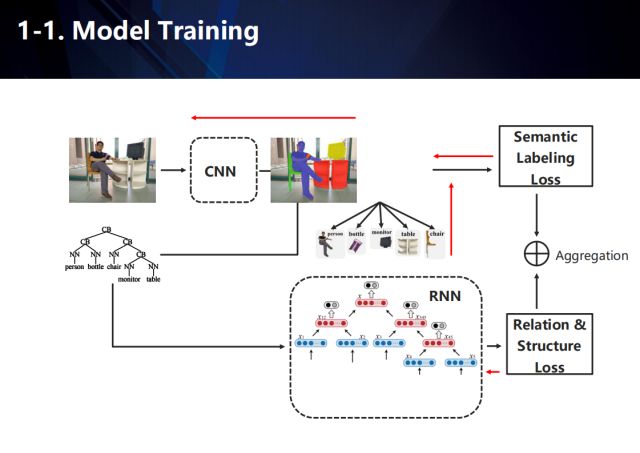
The goal of the whole network learning includes two, one is the scene semantic annotation information in the convolutional neural network part, and the other is the structural analysis result in the recursive neural network part. In the process of training, because the image data lacks corresponding scene structure information, we need to estimate it to train the convolutional neural network and the recursive cyclic neural network.
To put it simply, the focus of this work is to achieve the following two goals: (1) semantic annotation information, including the location of the semantic entity and the interaction between the semantic entities, and (2) the inheritance structure in the semantic entity.
The CNN-RNN joint structure used in this paper differs from the single RNN method in that the model predicts the relationship between child nodes and parent nodes. Among them, for semantic annotation, we use the CNN model to generate feature representations for each entity class, and group adjacent pixels and use the same label for the same category. Using the features generated by CNN, we design the RNN model to generate an image understanding tree to predict the relationship between objects and inheritance structure, including four parts, semantic mapping (single layer full connection layer), fusion (two child nodes combined to generate one Parent node), classifier (one of the subnetworks used to determine the relationship between the two nodes, and uses the characteristics of the parent node as input), the scorer (another subnetwork, which measures the confidence of the two nodes).
The method has two inputs in the learning process, one is an image, the other image corresponds to the sentence, the image is input into the CNN, and the entity class feature expression of the image is obtained, and the sentence is decomposed into a semantic tree by the semantic parse tree. The entity class obtained by the image is input into the RNN network together with the semantic spanning tree, and the semantic annotation of the image is used to train with the associated structural tree to obtain the expected result.

Semantic Segmentation and Scenario Structured Analysis The experimental results on the PSACAL VOC 2012 and SYSU-Scene evaluation sets are shown in the figure.
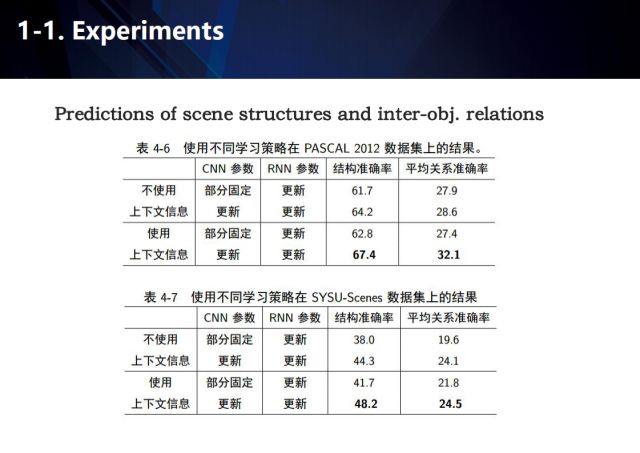
Here are the results of using different learning strategies on the PASCAL 2012 dataset. It can be seen that contextual information has proven to be an effective aid.
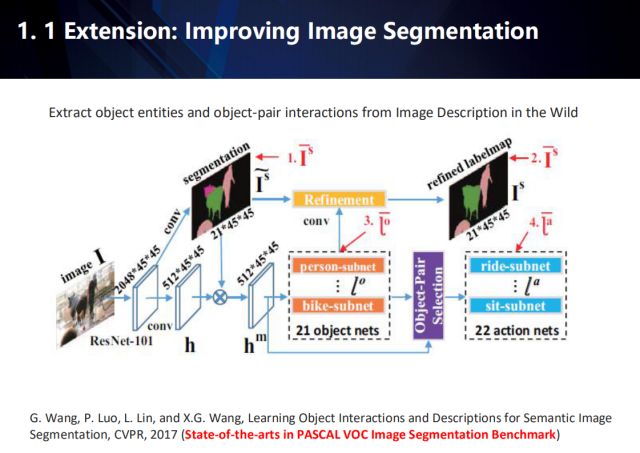
It can also be extended to the field of image semantic segmentation. This work was published in CVPR 2017 and is currently state-of-the-arts on the PASCAL VOC dataset.
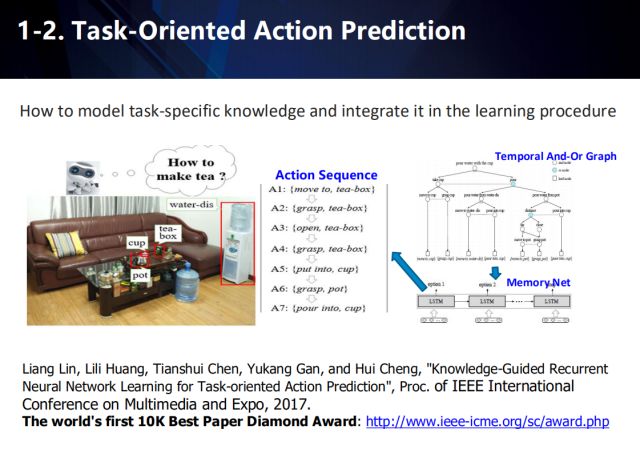
In addition, in task-oriented motion prediction, weak supervised learning can also be used to solve the problem that requires a large amount of information. This work won the World's First 10K Best Paper Diamond Award by ICME 2017.
For the first time, this work proposes a task-oriented motion prediction problem, that is, how to automatically generate an action sequence that can complete a specified task in a specific scenario, and collect data for the problem. In this paper, the authors propose long-short-term memory neural network (LSTM) for motion prediction and propose a multi-stage training method. In order to solve the problem of insufficient sample annotation in the learning process, the first phase adopts the time domain and or graph model (And-Or Graph, AOG) to automatically generate action sequence sets for data enhancement, and use the enhanced data in the next stage. Training action prediction network. Specific steps are as follows.
1) In order to model task knowledge, this paper introduces the time-domain and or-Or Graph (AOG) model expression task. The AOG consists of four parts: the root node representing the task, the non-terminal node set, the terminal node set, and the weight distribution set. Non-terminal nodes include nodes and or nodes. Wherein, the node indicates that the action of the node is decomposed into sub-actions having a time series relationship, or the node indicates a different manner in which the action of the node can be completed, and one of the child nodes is selected according to the probability distribution P. The terminal node includes atomic actions associated with the task.
2) Due to the timing dependencies existing in the AOG definition, the paper uses the depth-first traversal method to traverse each node, and uses the or-picture long-term memory model (AOG-LSTM) to predict the branch selection of the node.
3) Due to the very strong timing dependence of atomic motion sequences, the paper also designed an LSTM (Action-LSTM) to predict the atomic motion at each moment in time. Specifically, the atomic action Ai consists of a native action and a related object, which can be expressed as Ai=(ai, oi). In order to reduce the complexity of the model and the variability of the prediction space, the paper assumes that the predictions of the native motion and related objects are independent and predict separately.
Progressive and Cost-effective Learning

Then introduce the self-driven, cost-effective learning method.
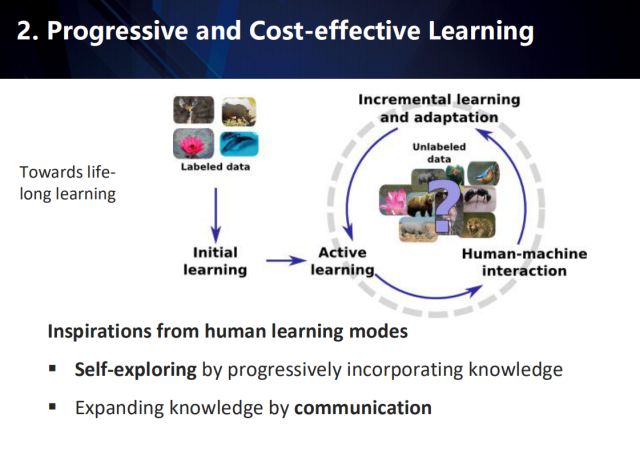
Such methods are inspired by the human learning model: first, self-exploration in the gradual integration of the learned knowledge, and second, the continuous expansion of knowledge in the process of communication to achieve the purpose of lifelong learning. As shown in the above figure, in the initial stage of learning, the existing annotation data is used for initialization learning, and then in a large amount of unlabeled data, sample mining is continuously performed in a human-machine collaborative manner to incrementally learn the model and adapt the unlabeled data. .

Course learning and self-paced learning are effective ideas in a self-driven, cost-effective learning approach.
The basic idea of ​​course learning is one of the pioneers of deep learning. The team of Professor Yoshua Bengio was presented at the ICML meeting in 2009. In 2014, Lu Jiang et al. proposed the axiomatization conditions for self-step learning. It also shows that for different applications, various practical course learning programs can be extended according to the axiomatic criteria. These methods first learn from the simple aspects of the task to obtain simple and reliable knowledge; then gradually increase the difficulty to transition to learning more complex and professional knowledge to complete the understanding of complex things.

In the target detection task, using a large number of unlabeled or partially labeled data for training, despite the challenges, is still a cost-effective way of actual visual tasks. For this challenge, it is often solved by active learning. At present, the active learning method often uses the latest detector to find a complex example that is indistinguishable from the detector according to a reliability threshold. Optimize detector performance by proactively labeling these samples. However, these methods of active learning have neglected a large number of simple examples.
So how do you take into account a small number of complex examples and make full use of a large number of simple examples?
We propose an Active Sample Mining (ASM) framework, as shown in the figure above. For a large number of unlabeled test data, we use the latest detectors for detection and sort the test results by reliability. For the high reliability test results, we directly use the test results as their unlabeled information; for a small number of low-reliability test results, we use active learning to mark. Finally, use this data to optimize detector performance.
Specifically, we use two different sets of sample mining strategy strategy functions: one for the automatic pseudo-labeling phase of high-confidence samples and the other for the manual labeling phase of low-confidence samples. We have further introduced a dynamic selection function to seamlessly determine which of the above stages is used to update the labels of unlabeled samples. In this way, our self-monitoring process and active learning process can work together and seamlessly switch to sample mining. In addition, the self-monitoring process also considers the guidance and feedback of the active learning process, making it more suitable for large-scale object detection. Specifically, we introduced two courses: the Self-Supervised Learning Curriculum (SSC) and the Active Learning Curriculum (ALC). SSC is used to indicate that a group has high prediction confidence and can control automatic pseudo-labeling of unlabeled samples, while ALC is used to represent very representative and suitable for constraining samples that need to be manually labeled. It is worth noting that during the training phase, SSC selects pseudo-label samples for network retraining from simple to complex. In contrast, ALC intermittently adds manually labeled samples to the training in a complex to simple manner. Therefore, we believe that SSC and ALC are dual courses that complement each other. Updated through an active learning process, these two dual courses can effectively guide two completely different learning models to mine massive unlabeled samples. This makes our model improve the robustness of the classifier to noise samples or outliers, and also improves the accuracy of detection.

Interpretation: The above optimization formula consists of (W, Y, V, U), where W refers to the model parameters (the parameters of the object detector, our article is Faster RCNN or RFCN). Y refers to the pseudo-labeled category of the proposal generated by the object detector under automatic labeling. V={v_i}^N_{i=1} refers to the empirical loss weight for each proposal training instance in the self-paced learning (self-supervised process in the above formula), the value of v_i is A continuous value m-dimensional vector of [0,1) (m is the number of categories). U={u_i}^N_{i=1} refers to the empirical loss weight for each training instance under active learning. u_i takes a value of {0,1} binary scalar.
W is the parameter we want to learn, and the rest of Y, V, and U can be regarded as hidden variables to be inferred to learn W. The latter two are weighted hidden variables, which are applied to each sample training loss based on a selection function (selector). Specifically, the optimization of W is based on the weighted sum of empirical losses. Therefore, before each optimization of W, we must know Y (because the empirical loss is the discriminant error, there is no pseudo-label (Y) given under the self-step learning process, all data can only be manually labeled with AL, the whole The method degenerates into full supervised learning). At the same time, before optimizing W and Y, we must know the values ​​of U and V (know the value of each u_i and v_i, in order to determine which training instance's y value needs manual labeling (autonomous learning AL), those need machine automatic inference (Self-supervised process SS).); At the same time, knowing each u_i and v_i can infer the training weight of the empirical error based on the selector). Given that the sample i is based on the range of u_i and v_i and the selector, it can be seen that the corresponding sample of u_i=1>v_i^{j} is selected as the artificially labeled object of active learning, u_i=0<=v_i^{j} The corresponding sample will be automatically labeled.

Thus, the problem lies in how to infer the two sets of weighted hidden variables U and V. It is easy to see that U and V are jointly inferred, and how U and V are chosen is determined by the empirical loss of each training instance and its respective control functions (f_SS, f_AL). The specific explanation of f_SS can be referred to self-paced curriculum learning. The simple understanding is to select the samples with less training loss for learning. This shows that the smaller the training loss, the greater the weight. As the lambda grows larger (lambda and gamma grow larger during the optimization process), the training begins to accept samples with greater training errors. In contrast to f_AL, active learning will initially select and manually label samples from which the training error is large (the sample error is set to zero, which is selected as the self-supervised process and automatically labeled). As gamma increases, active learning begins to accept samples of smaller errors.
The model function f_SS represents a greedy self-supervising strategy. It greatly saves the amount of manual annotation, but there is nothing to do with the semantic deterioration caused by the cumulative prediction error. Also, f_SS is greatly dependent on the initial parameter W. Since the model function f_AL exists, we can effectively overcome these shortcomings. f_AL selects the sample for post-processing by the user, and the manual annotation obtained by f_AL is considered reliable, and this process should continue until the end of the training. It is worth mentioning that pseudo-labeling by f_SS is only reliable in training iterations and should be appropriately adjusted to guide the learning of more robust network parameters at each stage. In fact, f_SS and f_AL are acting simultaneously with each sample, which would be equivalent to a minimax optimization problem.
On the other hand, U and V need to consider the information that has been manually marked by the person in active learning in the previous stage when inferring. We used the hand-marked information of the previous people to define two U and V-based value constraints called Dual Curricula. The constraint item will be self-learned for the selected training sample. If the sample belongs to one of the m categories, we set the u and v values ​​to 1; if the sample is not in the m categories, we Set its u and v values ​​to 0. This means that our training framework can accommodate new categories of excavations without allowing the new category to affect the training of the detector. V^{\lambda}_{i} and U^^{\lambda}_{i} constrain the u and v values ​​based only on the results of the previous AL selection.
In terms of image, we use two different sample mining strategy strategy functions: one for automatic false labeling mode for high confidence samples and the other for manual labeling mode for low confidence samples. We have further introduced a dynamic selection function to seamlessly determine which of the above stages is used to update the labels of unlabeled samples. In this way, our self-monitoring process and active learning process can work together and seamlessly switch to sample mining. In addition, the self-monitoring process also considers the guidance and feedback of the active learning process, making it more suitable for large-scale object detection. Specifically, we introduced two courses: the Self-Supervised Learning Curriculum (SSC) and the Active Learning Curriculum (ALC). SSC is used to indicate that a group has high prediction confidence and can control automatic pseudo-labeling of unlabeled samples, while ALC is used to represent very representative and suitable for constraining samples that need to be manually labeled. It is worth noting that during the training phase, SSC selects pseudo-label samples for network retraining from simple to complex. In contrast, ALC intermittently adds manually labeled samples to the training in a complex to simple manner. Therefore, we believe that SSC and ALC are dual courses that complement each other. Updated through an active learning process, these two dual courses can effectively guide two completely different learning models to mine massive unlabeled samples. This makes our model improve the robustness of the classifier to noise samples or outliers, and also improves the accuracy of detection.

The joint inference based on u and v constitutes a minmax optimization problem that can be based on training instance decomposition. For each training instance u and v, we prove that under certain conditions, the inference has a closed solution based on the above expression (this is a bit complicated, please refer to our article). Probably means that when considering the category empirical error sum of the training instance i, the u_i value will converge to 1 (the first case in braces) when it is greater than the first threshold. Since v^{j}_i<1, we know that the instance will be selected for manual annotation. On the other hand, the u_i value converges to zero when the category empirical error is less than another threshold (the first inequality of the second line of braces). Since v^{j}_i>=0, we know that the instance will be selected as the machine automatic labeling, and at the same time, according to the error size, corresponding weights are given accordingly. When the error is larger, the automatic labeling is more likely to be wrong, so the weight is automatically given smaller. When it is greater than a certain range (the second inequality of the second line of braces), both v and u will be zero at the same time, which means that the sample does not participate in this round of training.
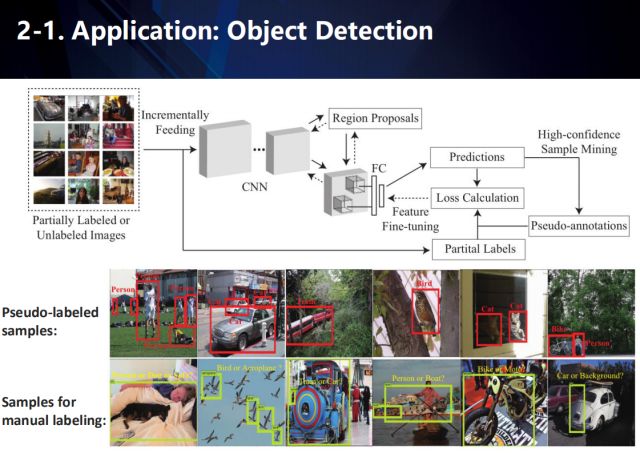
The figure above shows the application of the proposed framework (ASM) in target detection.

In the PASCAL VOC 2007/2012 results, our method can achieve state-of-the-arts detection performance by using only about 30~40% of the annotation data.

How to use a lot of original video to learn
A similar strategy can be applied to human segmentation tasks. We use human detectors and unsupervised segmentation methods to generate human masks from a large number of original videos (from YouTube). These mask information can be used as the annotation information of the segmentation network. At the same time, combined with the reliability map of the segmentation network output, the candidate region results extracted by the human detector are corrected to generate a better human body mask.
Unsupervised Domain Adaptation

In order to adapt to the distribution of data between different domains and solve the problem of lack of data annotation for target tasks, we will explore adaptive learning methods in unsupervised domain, including single data source domain adaptation and multi-data source domain adaptation.
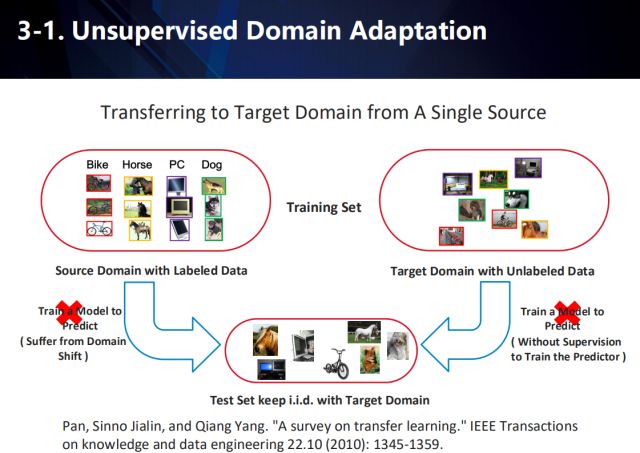
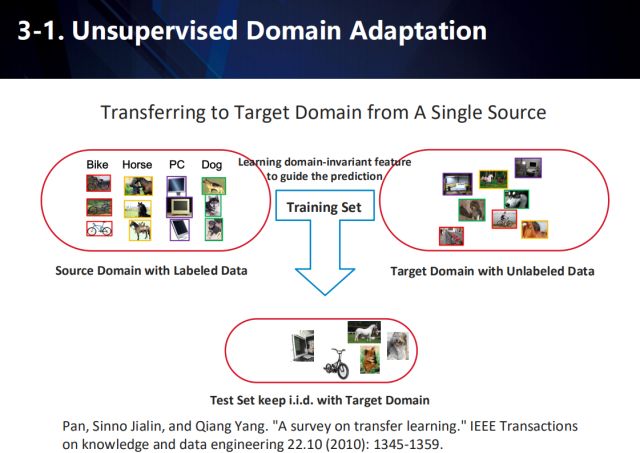
Single data source domain adaptation
In an application scenario, there is often too little data available in one domain, and sufficient data is available in other similar domains. Therefore, a series of migration learning methods are derived to achieve cross-domain adaptation. For example, in the illustrated task, the data of the source domain is generally tagged, and the data of the target domain not only has different distributions from the data in the source domain, but often has no annotation information. Therefore, the performance of the algorithm on the target domain data is improved by migrating the learned knowledge from the source domain to the target domain.
å› æ¤ï¼Œéœ€è¦è”åˆæœ‰æ ‡æ³¨çš„æºåŸŸæ•°æ®å’Œæ— æ ‡æ³¨çš„ç›®æ ‡åŸŸæ•°æ®ï¼Œæ¥å¦ä¹ ä¸€ä¸ªä¸ŽåŸŸæ— å…³çš„ç‰¹å¾ï¼Œæ¥è¿›è¡Œæœ€ç»ˆåœ¨ç›®æ ‡åŸŸä¸Šçš„预测。
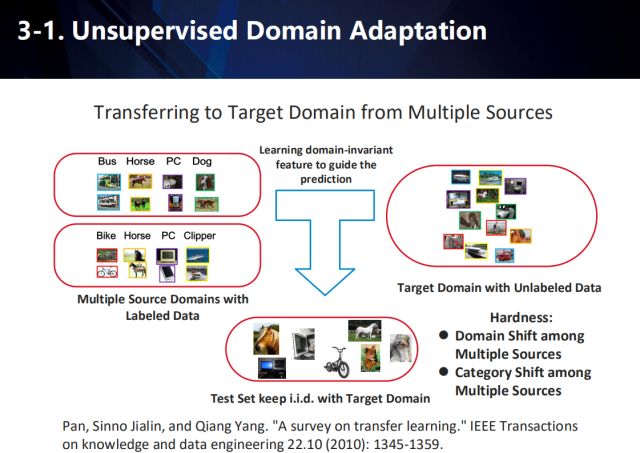
多数æ®æºé¢†åŸŸè‡ªé€‚应
而对于从多数æ®æºå‘ç›®æ ‡åŸŸè¿ç§»å¦ä¹ çš„æƒ…å†µï¼Œå°†æ›´åŠ å¤æ‚,需è¦è€ƒè™‘:1. 多ç§æºåŸŸæ•°æ®æœ¬èº«ä¹‹é—´å…·æœ‰åå·® 2. 多ç§æºåŸŸæ•°æ®é—´ç±»åˆ«å˜åœ¨å差。
å› æ¤æˆ‘们æ出了一ç§å为“鸡尾酒â€çš„网络,以解决将知识从多ç§æºåŸŸçš„æ•°æ®å‘ç›®æ ‡åŸŸçš„æ•°æ®ä¸è¿ç§»çš„问题。
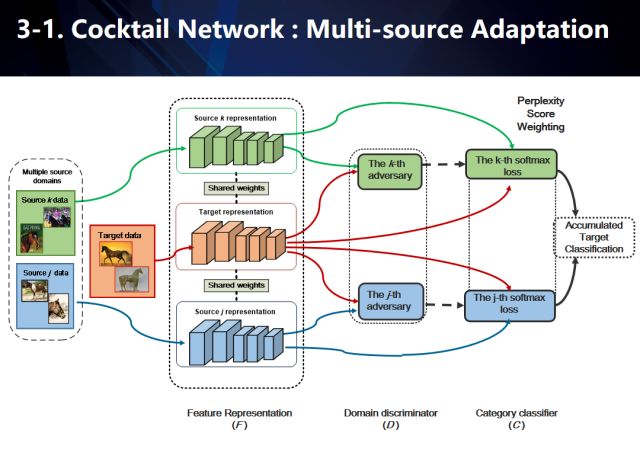
“鸡尾酒â€ç½‘络
鸡尾酒网络用于å¦ä¹ 基于多æºåŸŸï¼ˆæˆ‘们的图示仅简化地展示了j,k两个æºåŸŸï¼‰ä¸‹çš„域ä¸å˜ç‰¹å¾ï¼ˆdomain invariant feature)。在具体数æ®æµä¸ï¼Œæˆ‘们利用共享特å¾ç½‘络对所有æºåŸŸä»¥åŠç›®æ ‡åŸŸè¿›è¡Œç‰¹å¾å»ºæ¨¡ï¼Œç„¶åŽåˆ©ç”¨å¤šè·¯å¯¹æŠ—域适应技术(基于å•è·¯å¯¹æŠ—域适应(adversarial domain adaptation)下的扩展,对抗域适应的共享特å¾ç½‘络对应于生æˆå¯¹æŠ—å¦ä¹ (GAN)里é¢çš„生æˆå™¨ï¼‰ï¼Œæ¯ä¸ªæºåŸŸåˆ†åˆ«ä¸Žç›®æ ‡åŸŸè¿›è¡Œä¸¤ä¸¤ç»„åˆå¯¹æŠ—å¦ä¹ 域ä¸å˜ç‰¹å¾ã€‚åŒæ—¶æ¯ä¸ªæºåŸŸä¹Ÿåˆ†åˆ«è¿›è¡Œç›‘ç£å¦ä¹ ,è®ç»ƒåŸºäºŽä¸åŒæºç±»åˆ«ä¸‹çš„多个softmax分类器。注æ„到,基于对抗å¦ä¹ 的建模,我们在得到共享特å¾ç½‘络的åŒæ—¶ï¼Œä¹Ÿå¯ä»¥å¾—到多个æºåˆ†åˆ«å’Œç›®æ ‡åŸŸå¯¹æŠ—的判别器。这些判别器在对于æ¯ä¸€ä¸ªç›®æ ‡åŸŸçš„æ•°æ®ï¼Œéƒ½å¯ä»¥ç»™å‡ºè¯¥æ•°æ®åˆ†åˆ«ä¸Žæ¯ä¸€ä¸ªæºåŸŸä¹‹é—´çš„混淆度(perplexity scoreï¼‰ã€‚å› æ¤ï¼Œå¯¹äºŽæ¯ä¸€ä¸ªæ¥è‡ªç›®æ ‡åŸŸçš„æ•°æ®ï¼Œæˆ‘们首先利用ä¸åŒæºä¸‹çš„softmax分类器给出其多个分类结果。然åŽï¼ŒåŸºäºŽæ¯ä¸€ä¸ªç±»åˆ«ï¼Œæˆ‘们找到包å«è¯¥ç±»åˆ«çš„所有æºåŸŸsoftmax分类概率,å†åŸºäºŽè¿™äº›æºåŸŸä¸Žç›®æ ‡åŸŸçš„混淆度,对分类概率å–åŠ æƒå¹³å‡å¾—到æ¯ä¸ªç±»åˆ«çš„åˆ†æ•°ã€‚ç®€è€Œè¨€ä¹‹å°±æ˜¯ï¼Œè¶Šè·Ÿç›®æ ‡åŸŸç›¸è¯†çš„æºåŸŸæ··æ·†åº¦ä¼šæ›´é«˜ï¼Œæ„味ç€å…¶åˆ†ç±»ç»“果更å¯ä¿¡ä»Žè€Œå…·æœ‰æ›´é«˜çš„åŠ æƒæƒå€¼ã€‚
需è¦æ³¨æ„的是,我们并没有直接作用于所有softmax分类器上å而是基于æ¯ä¸ªç±»åˆ«åˆ†åˆ«è¿›è¡ŒåŠ æƒå¹³å‡å¤„ç†ã€‚è¿™æ˜¯å› ä¸ºåœ¨æˆ‘ä»¬çš„å‡è®¾ä¸‹ï¼Œæ¯ä¸ªæºçš„类别ä¸ä¸€å®šå…±äº«ï¼Œä»Žè€Œsoftmax结果ä¸èƒ½ç®€å•ç›¸åŠ 。当然,我们的方法也适用于所有æºå…±äº«ç±»åˆ«çš„æƒ…å†µï¼Œè¿™æ ·æˆ‘ä»¬çš„å…¬å¼ä¼šç‰ä»·äºŽç›´æŽ¥å°†softmaxåˆ†ç±»ç»“æžœè¿›è¡ŒåŠ æƒç›¸åŠ 。
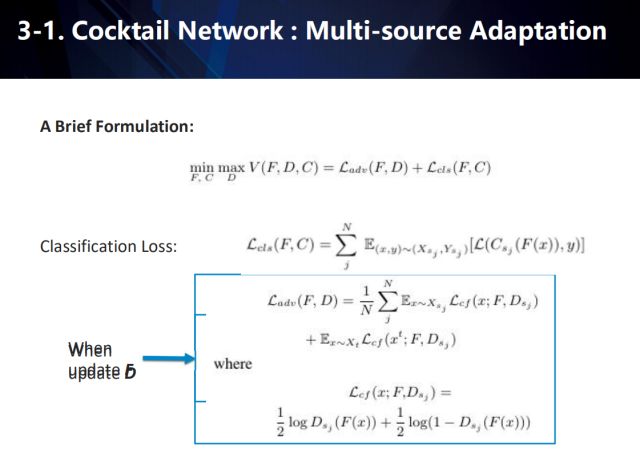
å…¶ä¸ï¼ŒL_adv 是对抗æŸå¤±ï¼Œå½“è®ç»ƒåˆ¤åˆ«å™¨æ—¶ç”¨ä¼ 统的GAN loss,当è®ç»ƒfeature extractor时用confusion loss。L_cls是多æºåŸŸï¼ˆmultiple source domains)分类æŸå¤±ï¼ŒC为多æºåŸŸsoftmax分类器。N是source的数目,s_j 代表第j个source,C_{s_j}代表第j个sourceçš„softmax 分类器(用Cæ¥è¡¨ç¤ºå…¨éƒ¨source的分类输出),D_{s_j}代表第j个sourceè·Ÿtarget对抗的判别器(用Dæ¥è¡¨ç¤ºå…¨éƒ¨çš„对抗结果),F为feature extractor。

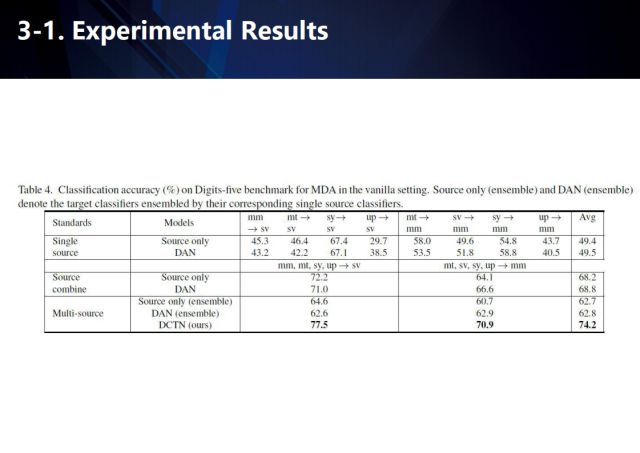
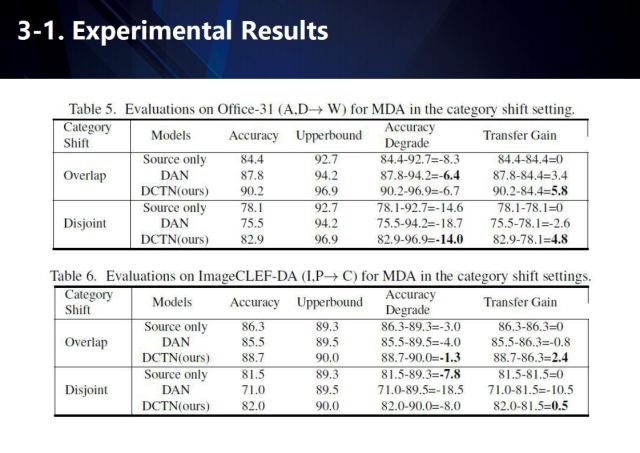
我们分别在Office-31ã€ImageCLEF-DAã€Digit-fiveæ•°æ®é›†ä¸Šè¿›è¡Œäº†æµ‹è¯„,我们的方法å–得了很好的结果。

Fiber Optic Cabinet,Fiber Cabinet,Fiber Distribution Cabinet,Outdoor Fiber Cabinet
Cixi Dani Plastic Products Co.,Ltd , https://www.danifiberoptic.com